Bayer Bäume

blogger
Inhaltsverzeichnis
1. Praxisbezug und Implementierung
1.1 Suchen in Bayer-Bäumen
1.2 Einfügen in Bayer-Bäume
1.3 Löschen aus Bayer-Bäumen
1.4 Logischer Aufbau einer Implementierung
1.5 Vergleich und Besonderheiten: Implementierung / Bayer-Baum
1.6 Verbesserungen
2. Fazit
3. Zum Schluß
3.1 Literaturverzeichnis
3.2 Quellenverzeichnis
Anhang : Eine Bayer-Baum-Implementierung in TC++ 1.0
1. Praxisbezug und Implementierung
Vorbemerkungen
Sei k ein ganze Zahl k > 0. Ein B-Baum der Klasse k ist entweder leer oder ein geordneter Baum mit folgenden Eigenschaften :
- Jeder Pfad von der Wurzel zu einem Blatt hat die gleiche Länge.
- Jeder Knoten außer der Wurzel und den Blättern hat mindestens k + 1
Nachfolger. Die Wurzel ist ein Blatt oder hat mindestens zwei Nachfolger.
- Jeder Knoten hat höchstens 2 * k + 1 Nachfolger.
- Jedes Blatt mit Ausnahme der Wurzel als Blatt hat mindestens k und
höchstens 2 * k Daten.
Mindestfunktionen in einem B-Baum-System :
- Suchen
- Einfügen
- Löschen
- Reorganisieren
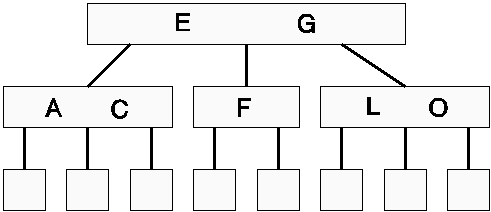
 1.1 Suchen in Bayer-Bäumen
1.1 Suchen in Bayer-Bäumen
Das Suchen nach einem Schlüssel x in einem B-Baum der Ordnung k kann als natürliche Verallgemeinerung des von binären Suchbäumen bekannten Verfahrens aufgefaßt werden1. Man beginnt bei der Wurzel und stellt zunächst fest, ob der gesuchte Schlüssel x einer der im gerade betrachteten Knoten p gespeicherten Schlüssel s1,...,s2k (mit den Zeigern p0,...,p2k) ist. Ist das nicht der Fall, so bestimmt man das kleinste i, 1 ? i ? 2 * k, für das x < si ist, falls es ein solches i gibt; sonst ist x > s2k. Im ersten Fall setzt man die Suche bei dem Knoten fort, auf den der Zeiger pi-1 zeigt; im letzten Fall folgt man dem Zeiger p2k. Das wird solange fortgesetzt, bis man den gesuchten Schlüssel gefunden hat oder die Suche erfolglos in einem Blatt endet. Es ist klar, daß man im schlechtesten Fall höchstens alle Knoten auf einem Pfad von der Wurzel zu einem Blatt betrachten muß. Man kann es offen lassen, wie man die Suche nach einem x eines Knotens p mit den Schlüsseln s und den Zeigern p durchführt. Um dasjenige i zu finden, für das gilt, x = si bzw. das kleinste i zu bestimmen für das x < si ist, bzw. festzustellen, daß x > s2k ist kann man beispielsweise sowohl lineares als auch binäres Suchen verwenden. Da diese Suche in jedem Fall im Hauptspeicher stattfindet, beeinflußt sie die Effizienz des gesamten Suchverfahrens weit weniger als die Anzahl der Knoten, die betrachtet werden müssen, die ja unmittelbar mit der Zahl der bei der Suche nach x erforderlichen Hintergrundspeicherzugriffe zusammenhängt.

1.2 Einfügen in Bayer-Bäume
Um einen neuen Schlüssel x in einen B-Baum einzufügen, sucht man zunächst im Baum nach x. Da x im Baum noch nicht vorkommt, endet die Suche erfolglos in einem Blatt, welches die erwartete Position des Schlüssels x repräsentiert.
Für die weitere Bearbeitung befindet sich also der entsprechende Knoten jetzt im Hauptspeicher1.
Einfügen durch Spalten2
Zu Abb. 3 a
Zunächst ist der Baum leer, und die Pointervariable Wurzel hat den Wert NULL, zeigt also auf nichts.
Zu Abb. 3 b
Nach dem das Datum "A" eingefügt worden ist, entsteht die zweite Struktur.
Der Baum besteht nur aus einem Knoten, der zugleich Wurzel und Blatt ist.
Die B-Baum-Eigenschaften sind nicht verletzt.
Zu Abb. 3 c
Analog werden die Element "B", "C" und "D" eingefügt.
Zu Abb. 3 d
Komplizierter wird es, wenn das Datum "E" mit aufgenommen werden soll. Beim vergleichbaren 5-Wege-Suchbaum würde jetzt rechts von "D" ein neuer Knoten erzeugt. Die B-Baum-Eigenschaften schreiben aber vor, daß alle Wege von der Wurzel zu den Blättern gleich lang sein sollen.
Also greift man zu folgendem Trick :
Der Knoten, in dem eingefügt werden soll, wird um ein Element erweitert, und es entsteht ein Knotenüberlauf. Nach diesem Einfügen enthält der Knoten auf jeden Fall eine ungerade Anzahl von Elementen, weil 2 * k + 1 für alle k ungerade ist.
Zu Abb. 3 e
Dieser "große" Knoten kann also in zwei Söhne zerlegt werden, und nur das mittlere Element verbleibt im Vaterknoten. Das Einfügen eines Elementes hat demnach die Erzeugung von zwei neuen Knoten bewirkt, und der neue Baum genügt wieder den B-Baum-Eigenschaften
Zu Abb. 3 f
Neue Elemente werden grundsätzlich in einem Blatt eingefügt. Deswegen landen die Elemente "F" und "G" nicht in der Wurzel, sondern im rechten Blatt.
Zu Abb. 3 g
Als nächstes soll das Element "H" eingefügt werden. Das Element muß in das Blatt eingefügt werden, in dem schon die Elemente "D", "E", "F" und "G" sind. Es entsteht ein Überlauf, das Blatt muß also gesplittet werden. Das mittlere Element ("F") gelangt dabei in den darüber liegenden Knoten.
Anmerkung
Es kann natürlich passieren, daß das mittlere Element in der höheren Ebene wieder einen Split-Vorgang hervorruft, wenn dieser Knoten schon voll ist. Diese Reorganisation kann also recht komplex sein und läßt sich nur mit rekursiven Prozeduren sinnvoll lösen. Insgesamt garantiert dieser Einfügemechanismus die
B-Baum-Eigenschaften, der Baum kann nie zu einer linearen Liste entarten und behält somit seine guten Sucheigenschaften.

 1.3 Löschen aus Bayer-Bäumen
1.3 Löschen aus Bayer-Bäumen
Das Einfügen ist nur eine der beiden benötigten Operationen. Natürlich sollten Daten auch wieder gelöscht werden können. Jedoch ist das Löschen aus B-Bäumen noch ein wenig aufwendiger.
Fall 1.1
Das zu löschende Element befindet sich in einem Blatt. Dieses Blatt enthält mehr als k Daten. In diesem Fall kann das Element einfach gelöscht werden, ohne den Baum zu reorganisieren. Der modifizierte Baum genügt wieder den
B-Baum-Eigenschaften.
Fall 1.2
Enthält das Blatt jedoch genau k Elemente, entsteht durch das Löschen ein Unterlauf. Denn jeder Knoten eines B-Baumes muß mindestens k Elemente enthalten. Was bei einem Unterlauf getan werden muß, dürfte klar sein:
Von irgendwoher müssen Elemente genommen werden, um das entsprechende Blatt aufzufüllen. Die B-Baum-Eigenschaften besagen ja, daß jedes Blatt außer
der Wurzel mindestens k Elemente enthält. Es ist naheliegend, diese zusätzlichen Elemente von einem Nachbarknoten zu nehmen.
Hier liegt aber auch gleich das Problem : Wenn der Nachbarknoten nur k Elemente hat, kann dieser keine an den Knoten mit dem Unterlauf abgeben.
Fall 1.2 a
Zunächst soll der Nachbarknoten mehr als k Elemente besitzen. Jetzt können Elemente wie Perlen an einer Kette vom linken Knoten über den gemeinsamen Vaterknoten zum rechten Knoten fließen. Dieser Vorgang wird solange wiederholt, bis beide Knoten ausgeglichen sind. Deswegen nennt man diese Methode auch
"Löschen durch Ausgleichen" (Abb. 4). Sie stört die lexikografische Ordnung nicht, und es entsteht wieder ein B-Baum, der den B-Baum-Eigenschaften entspricht.
Fall 1.2 b
Das obenerwähnte Verfahren schlägt natürlich fehl, wenn der Nachbarknoten selber nur k Elemente besitzt. In diesem Fall werden beide Knoten zu einem einzigen Knoten verschmolzen. Das Element "b" des Vaterknotens nimmt man ebenfalls in den neuentstehenden Knoten auf, und es entsteht ein Blatt, mit genau 2 * k
Elementen. Dieser Vorgang wird mit "Löschen durch Mischen bezeichnet" (Abb. 5); der Mischvorgang ist das genaue Gegenstück zum Teilungsprozeß beim Einfügen. Da der Mischvorgang dem Vaterknoten das Element "b" entzieht, muß es dort gelöscht werden. Wiederum entsteht ein rekursiver Prozeß, der sich schlimmstenfalls bis zur Wurzel fortsetzt.
Anmerkung
Ist der Knoten, aus dem gelöscht werden soll, der äußerst linke Knoten, so wird als Knoten für den Ausgleich bzw. für das Mischen der rechte Nachbar herangezogen. Ist der Knoten, aus dem gelöscht werden soll, der äußerst rechte Knoten so ist es genau umgekehrt. Das hat zur Folge, daß je nach Position des Knotens, aus dem gelöscht werden soll, die Elemente zum Ausgleich bzw. zum Mischen aus dem entsprechenden Nachbarknoten genommen werden müssen.
Fall 2
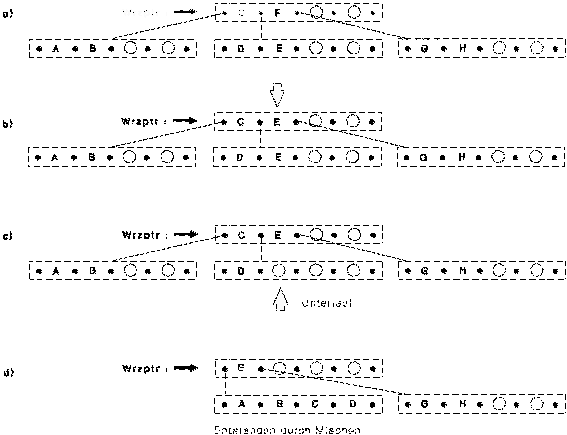
Das zu löschende Element befindet sich nicht in einem Blatt, sondern in einem inneren Konten. Hier scheint der Reorganisationsaufwand besonders groß zu sein, da durch das Löschen ein Loch entstehen würde. Die Teilbäume darf man natürlich nicht mitlöschen (wie z.B. "G" und "H" beim Löschen von "F").
Glücklicherweise gibt es für diesen Fall einen einfachen Trick:
Das zu löschende Element wird durch das größte Datum im linken Teilbaum (direkter linker Nachbar) ersetzt. Anschließend kann dann dieses größte Element normal gelöscht werden, da es sich immer auf einem Blatt befindet (das größte Element in einem Baum oder Teilbaum befindet sich immer in einem Blatt !).
Dieser kleine Trick reduziert das Problem des Löschens von inneren Elementen auf das Löschen in Blättern. In Abb. 6 wird "F" erst durch "E" ersetzt, was die lexikografische Ordnung nicht verletzt und dann das Element "E" im linken Teilbaum gelöscht.
1.4 Logischer Aufbau einer Implementierung
Beschreibung der B-Baum-Struktur1
Sei k wieder eine ganze Zahl k > 0. Der implementierte B-Baum ist entweder leer oder ein geordneter Baum mit Folgenden Eigenschaften:
- Jeder Pfad von der Wurzel zu einem Blatt hat die gleiche Länge.
- Jeder Knoten hat mindestens 2 Nachfolger. Die Wurzel ist ein Blatt oder hat mindestens 2 Nachfolger.
- Jeder Knoten hat höchstens 2 * k Nachfolger.
- Jedes Blatt hat mindestens 1 und höchstens 2 * k Elemente.
- Wird ein neuer Knoten (Blatt) durch Splitting erzeugt, so enthält der eine Knoten k und der andere k + 1 Daten.
- Ein Knoten wird dann gelöscht, wenn sein letztes Element gelöscht wird.
- Daten sind nur in den Blättern gespeichert.
- Innere Knoten enthalten die größten Schlüssel ihrer Teilbäume.
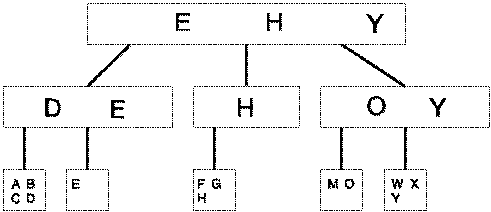 1.5 Vergleich und Besonderheiten : Implementierung / Bayer-Baum
1.5 Vergleich und Besonderheiten : Implementierung / Bayer-Baum
Da die Ordnung k eines B-Baumes normalerweise etwa zwischen 100 und 200 liegt, geht dadurch, daß die Daten nur in den Blättern gespeichert sind, nicht wesentlich viel an Speicherplatz verloren.
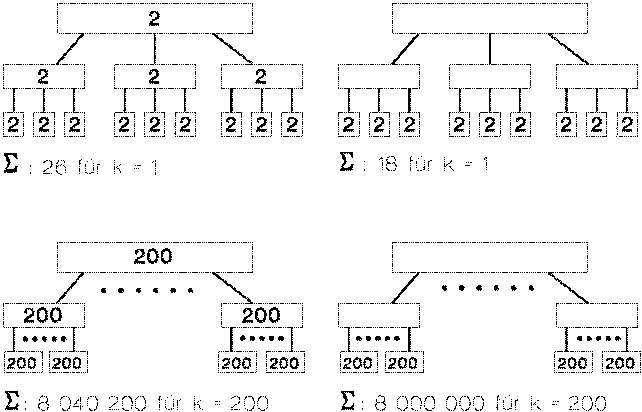
Für k = 1 hat der B-Baum etwa 45 % mehr Speicherkapazität als die Implementierung (26 / 18 * 100 % - 100 %). Für k = 200 hat der B-Baum nur noch 0.5 % (8 040 200 / 8 000 000) mehr Kapazität als die Implementierung. Man kann also davon ausgehen, daß mit steigendem k die Implementierung den originalen
B-Baum aproximiert. Das Beispiel zeigt, daß man bei einem normalen k von 200 eine fast optimale Annäherung der Speicherkapazität erreicht. B-Bäume werden normalerweise für große Datenmengen eingesetzt, insofern kann man davon ausgehen, daß der B-Baum und die Implementierung in Bezug auf die Speicher-kapazität gleichwertig sind.
Suchen bei der Implementierung
Im wesentlichen funktioniert das Suchen genauso wie bei einem normalen B-Baum. Jedoch muß man immer den gesamten Weg von der Wurzel bis zum Blatt absuchen. Aus Abb. 8 ist jedoch zu erkennen, daß B-Bäume besonders niedrig sind, sodaß dieser Nachteil nicht besonders ins Gewicht fällt.
Einfügen bei der Implementierung
Auch hier werden die Daten nur in die Blättern eingefügt. Eine Reorganisation muß nur dann durchgeführt werden, wenn der einzufügende Schlüssel größer ist als der größte Schlüssel im Teilbaum. Die Reorganisation wird dann rekursiv von dem entsprechenden Blatt bis zur Wurzel des entsprechenden Teilbaums durchgeführt. Bei einem Splitting wird in der darüberliegenden Stufe einfach nur der entsprechende Schlüssel eingefügt. Auch hier ergibt sich - wie auch beim originalen B-Baum - eventuell die entsprechende Reorganisation.
Löschen bei der Implementierung
Hier ergibt sich ein wesentlicher Vorteil der Implementierung gegenüber dem
B-Baum, da sich bei der Implementierung das Löschen nur auf die Blätter bezieht.
Eine Reorganisation muß nur dann durchgeführt werden, wenn das größte Element in einem Knoten gelöscht werden soll.Auch jetzt setzt sich die Reorganisation entsprechend weit nach oben fort, bis der entsprechende Schlüssel überall geändert ist. Ein Mischen oder Ausgleichen gibt es bei der Implementierung nicht. Die Knoten bleiben solange erhalten, bis ihr letztes Element gelöscht wird. Erst jetzt wird der entsprechende Platz an die Freispeicherverwaltung zurückgegeben. Der Vorteil liegt hier ganz klar beim geringen Reorganisationsaufwand. Der Nachteil, der sich vielleicht daraus ergeben könnte, ist daß man immer eine gewisse Anzahl von relativ leeren Knoten in der Datei hat, was auf jeden Fall einen Geschwindigkeitsvorteil mit sich bringt. Denn beim Einfügen in diese Knoten muß nur reorganisiert werden, wenn sich der größte Schlüssel ändert (für diese Knoten entfällt das Splitting). Normalerweise hält man Index und Daten voneinander getrennt, insofern wirkt sich die Anzahl dieser Knoten nur auf den Index aus. Wie schon erwähnt sind B-Baum-Dateien groß, sodaß die Anzahl der relativ leeren Knoten höchstens einen kleinen Prozentsatz ausmacht und somit vernachlässigt werden kann.
1.6 Verbesserungen
Index- und Datendatei
Man sollte immer mit einem getrennten Indexbereich (Indexdatei) und einem getrennten Datenbereich (Datendatei) arbeiten. Das Datenverwaltungssystem (DVS) greift nicht auf Datensätze, sondern nur auf Blöcke zu. Im BS 2000 ist die kleinste Blockeinheit eine PAM-Seite = 2 KB, und unter MS-DOS ist die kleinste Clustereinheit für HDs = 2 KB (für FDs 512 Bytes). Die dem Index zugrundeliegende
logische Blockgröße sollte im Overhead des Indexes gespeichert werden, wodurch eine Konvertierung in andere logische Blockgrößen leicht möglich wird. Die logische Blockgröße sollte immer ein ganzzahliges Vielfaches der physikalischen Speichereinheit sein, und logische sowie physikalische Blockgrenzen sollten in jedem Fall aufeinanderfallen. Nur so ist es möglich, einen logischen Block mit einem Hintergrundspeicherzugriff in den Hauptspeicher zu laden.
Beispiel : Annahme man legt den Wurzelblock unter MS-DOS in einer Datei ab Offset 200 ab, so muß das System Cluster 0 und Cluster 1 (zwei
Zugriffe) laden, damit die Wurzel (2 KB) in den Hauptspeicher gelangt.
Geht man von einer durchschnittlichen Schlüssellänge von 10 bis 20 Zeichen aus und rechnet den Platz für die entsprechenden Pointer dazu, so kann man in einem 2 KB Block ungefähr 100 bis 150 Elemente unterbringen.
Hält man Daten und Index vermischt, so ist dieses blockweise Laden nicht mehr möglich, da die Datensätze verschiedene Länge haben können (nur die Schlüssel müssen gleich lang sein) oder Datensätze über Blockgrenzen hinausgehen. In jedem Fall ist ein Datensatz mit seinen Daten länger als der Schlüssel selbst, wodurch bei vermischter Organisation weniger Elemente in einen Knoten passen. Das hat zur Folge, daß der B-Baum schneller in die Tiefe geht und zum Auffinden eines Datums somit mehr Speicherzugriffe erforderlich sind.
Hält man Index- und Datendatei getrennt, so kann man die Datensätze in der Datendatei mit und ohne Schlüssel speichern. Zusätzliches Speichern der Schlüssel in der Datendatei vergrößert diese nur geringfügig, da die Schlüssellänge normalerweise relativ klein gegenüber der Datensatzlänge ist.
Für den Fall, daß der Index aus irgendwelchen Gründen zerstört wird, ist er somit aus der Datendatei rekonstruierbar, was zur Datensicherheit beiträgt.
Knoten im RAM halten
Eine weiteren Geschwindigkeitsvorteil erhält man dadurch, daß man den Wurzelknoten (oder ganze Stufen) im RAM hält. Man spart somit bei jedem Suchen, Einfügen und Löschen einen Hintergrundspeicherzugriff, was einer Geschwindigkeitszunahme von 20 bis 30 % entspricht, denn B-Bäume haben normalerweise eine Tiefe von etwa 2 bis 4 Stufen. Ändert sich nun ein solcher speicherresistenter Block, so wird er abgespeichert. Eine andere Möglichkeit ist, daß in einem geänderten Block ein Flag gesetzt wird, welches aussagt, daß der Block verändert wurde. Am Ende des Programms werden dann alle Blöcke abgespeichert, bei denen oder für die ein entsprechendes Flag gesetzt ist.
Mehrdeutige Schlüssel
Bayer-Bäume arbeiten normalerweise nur mit eindeutigen Schlüsseln.Für bestimmte Systeme (z.B. Adressverwaltung) ist es jedoch notwendig, daß ein Mehrfachauftreten des "gleichen" Schlüssels gewährleistet sein muß.
Dies kann man mit einem Trick erreichen :
Man setzt den Schlüssel aus zwei Teilen zusammen. Aus einem signifikanten Teil (z.B der Name) und einer Erweiterung (z.B. eine Zahl wird vom System bestimmt). Dadurch hat man physikalisch eindeutige und logisch mehrdeutige Schlüssel. Wird nun ein Schlüssel gesucht, so wird die Erweiterung auf "0" gesetzt und die Suchprozedur gestartet. Wurde ein Datensatz gefunden, so wird seine Erweiterung entsprechend verändert (z.B. inkrementieren) und mit dem so erzeugten Schlüssel die Prozedur wieder aufgerufen. Dieser Vorgang wiederholt sich solange, bis kein Eintrag mehr gefunden wird. Nimmt man als Erweiterung z.B. ein Integerzahl von 2 Byte, so kann man dadurch 256 * 256 = 65536 Datensätze unterscheiden.
Reorganisation
Eine Möglichkeit, um die Reorganisation von B-Bäumen durchzuführen, ist beim Vater die Pointer auf die Söhne und bei den Söhnen Pointer auf den Vater zu speichern. Dadurch entsteht jedoch ein erhebliches Problem :
Wird ein Nichtblatt gesplittet, so wird die Hälfte des Inhalts in einen anderen, neu erzeugten Knoten verlegt (neuer physk. und log. Offset). Die Vaterpointer der verlegten Söhne, des neuentstandenen Vaters, zeigen aber immer noch auf den alten Knoten (das äquivalente Problem entsteht natürlich auch beim Mischen). Diese Vaterpointer müssen also alle geändert werden, was bei k = 100 ein erheblicher Aufwand ist.
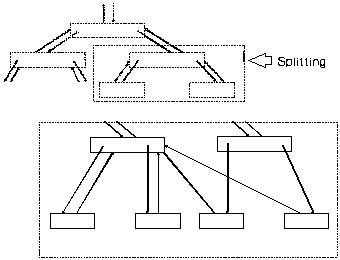
Die Söhne selbst befinden sich immernoch an der gleichen physikalischen Position, denn es wurde ja nur etwas im Vater der Söhne geändert. Die Reorganisation muß also nur die Stufe (und dort nur die entsprechenden Knoten), im Teilbaum unter dem Vaterknoten betrachten, die direkt darunter liegt. Diese Reorganisation pflanzt sich also nicht bis zu den Blättern fort.
Lösung: Bei B-Bäumen arbeitet man ohne Rückwärtsverkettung. Beim Durch suchen des Baumes von der Wurzel her merkt man sich alle Offsets der dabei durchlaufenen Knoten (z.B auf einem Stack). Muß jetzt eine Reor ganisation durchgeführt werden, so braucht man sich nicht anhand der Pointer vom Sohn zu Vater durch den Baum zu "hangeln" (Hintergrund speicherzugriffe), denn die benötigten Offsetadressen befinden sich schon im Hauptspeicher. 2. Fazit
Hier ist auf ein Zitat von Arno Puder zu verweisen :
"Zeit ist Geld - ist eines der Leitmotive unserer Gesellschaft, und auch die Informatiker müssen ihre Professionalität an der Geschwindigkeit ihrer Programme messen lassen. Dies gilt insbesondere im Bereich der Datenspeicherung und Datenwartung. Ist die Datenmenge groß, daß diese nicht mehr im Hauptspeicher abgelegt werden kann, müssen raffinierte Datenstrukturen her um die zeitaufwendigen Zugriffe auf die Massenspeicher optimal auszunutzen."
Doch ist die Datenstruktur alleine noch nicht der Schlüssel zur Geschwindigkeit.
Wie man dem Kapitel 1.6 - Verbesserungen - entnehmen kann, sollte man auch bei der Implementierung auf etwas Professionalität achten. Nur so ist es möglich Strukturvorteile völlig auszunutzen und zu optimalen Ergebnissen zu gelangen.
3. Schluß
3.1 Literaturverzeichnis
Knuth D. : Art of Computerprogramming
Mehlhorn : Effiziente Algorithmen
Ottmann T. / Widmayer P. : Algorithmen und Datenstrukturen,
BI Wissenschaftsverlag
3.2 Quellenverzeichnis
Puder A. Datenbäume
Heise Verlag, ct Mai 1989 Seite 177 ff
- Verwaltung großer Datenmengen
mit Bayer-Bäumen
Ottmann T. / Widmayer P. Algorithmen und Datenstrukturen
BI Wissenschaftsverlag Seite 312 bis 323
Anhang : Eine Bayer-Baum-Implementierung in TC++ 1.0
Auf den folgenden Seiten wird eine B-Baum-Implementierung vorgestellt, die mit Turbo C++ 1.0 unter MS-DOS programmiert wurde.
Die Implementierung setzt sich aus folgenden Dateien zusammen :
ISAM.TXT : Beschreibung aller Isam-Funktionen
ISAM.H : Headerdatei
ISAM.C : Implementierung der Isam-Funktionen
ISAMTST1.C : Ein Testprogramm mit eindeutigen Schlüsseln
ISAMTST2.C : Ein Testprogramm mit mehrdeutigen Schlüsseln
ISAM.MAK : Ein Makefile, zur Erzeugung einer
Isam-Bibliothek (ISAM.LIB)
Autor: Centurion
Im folgenden werden mit Pointer (ptr) RAM-Zeiger und mit Vektoren (vek)
Dateizeiger (long-Werte) bezüglich Dateibeginn bezeichnet.
Die Funktionen zur indexsequentiellen Dateiverarbeitung unterscheiden
beim Suchschlüssel, der ein String sein muß, zwischen Groß- und
Kleinbuchstaben. (Der erfahrene Anwender kann als Key jedoch auch mit
allen anderen Datentypen arbeiten !). Die Funktionen bauen einen
Bayer-Baum auf, der in seiner Baumtiefe nur durch die Speicherkapazität
des Speichermediums begrenzt wird. Die Blockgr?ße eines Indexblocks
des Bayerbaums beträgt normalerweise 2 Kb, kann jedoch zusätzlich
vom Anwender der Funktionen verändert werden.
Isamopen
--------
Syntax : void *isamopen(char *datname,unsigned reclen,unsigned keylen)
Parameter: datname: Dateiname der Indexsequenziellen Datei
(auch Pfad, max 80 Zeichen)
reclen : Datensatzlänge inklusive key
keylen : Indexschlüssellänge
Rückgabe : Bei Erfolg: Isamdateihandle :
void *isamhdl, ein Pointer zur Aufnahme
des Isamdateihandle muß vereinbart werden.
Ansonsten : NULL
Funktion : Öffnet ein indexsequentielle Datei. Als Dateiname muß der
Name der Datendatei übergeben werden (Es kann auch ein ganzer
Pfad übergeben werden). Der Datendateiname muß die
Extension `.dat` besitzen ! Der Indexdateiname
wird erzeugt, er besitzt die Extension `.idx`.
Die Schlüsselänge (keylen) darf nicht größer sein
als die Datensatzlänge (reclen). `Keylen` und `Reclen`
dürfen nicht kleiner sein als ein Byte. Der Key darf
nicht länger als 255 Bytes sein. Wird eine
existierende Datei mit falscher Schlüssellänge und/oder
falscher Datensatzlänge eröffnet, so werden Schlüssellänge
und Datensatzlänge auf den richtgen Wert korrigiert.
Isamclose
---------
Syntax : long isamclose(void *isamhdl)
Parameter: isamhdl: Isamdateihandle; muß definiert sein (z.B in main())
Rückgabe : Bei Erfolg: Positiver Wert
Bei Fehler: NULL
Funktion : Schließt eine Indexsequentielle Datei
Isamdel
-------
Syntax : long isamdel(void *isamhdl,void* isamrec)
Parameter: isamhdl: Isamdateihandle; muß definiert sein (z. B in main() )
isamrec: Pointer auf Key des Satzes, der gelöscht werden soll
Rückgabe : Bei Erfolg: Positiver Wert
Bei Fehler: NULL (Datensatz nicht vorhanden)
Funktion : Löscht einen Datensatz. `isamrec` ist ein Pointer auf einen
vom Anwender reservierten Speicherbereich an dem sich der
Suchschlüssel (String) des zu löschenden Datensatzes
befindet.
Isamread
--------
Syntax : long isamread(void *isamhdl,void *isamrec)
Parameter: isamhdl: Isamdateihandle (wird von Isamopen zurückgegeben)
isamrec: Pointer reservierten Speicherplatz für
Datensatz
Rückgabe : Bei Erfolg: Vektor (long-Wert); entspricht der Position
des Datensatzes in der Datendatei, relativ
zum Dateibeginn.
Bei Fehler: NULL, d.h. der Datensatz wurde nicht gefunden.
Funktion : Liest einen Datensatz aus einer indexsequentiellen Datei.
Isamrec ist ein Pointer auf den Suchschlüssel (string).
An der Position isamrec muß sich genügend Platz für einen
Datensatz befinden (mindestens reclen Bytes; siehe isamopen).
Bei Erfolg befindet sich der gelesene Datensatz an der
Position reclen (beginnend mit dem Key).
?ber den zurückgegebenen Vektor kann der Datensatz
direkt mit isamdatput() verändert werden, jedoch darf sich
der Key dann nicht ändern. Soll der Key geändert werden
muß isamwrite() benutzt werden !
Isamwrite
---------
Syntax : long isamwrite(void *isamhdl,void *isamrec,int mode)
Parameter: isamhdl: Indexdateihandle
isamrec: Pointer auf reservierten Speicherplatz
mode : Bestimmt die Arbeitsweise der Funktion
Rückgabe: mode 1 : Den Vektor an der sich der Datensatz in der
Datendatei befindet multipliziert mit -1
==> negativer Wert
Bei Fehler : NULL
mode 2 : den Vektor an der der Datensatz in der Datendatei
gespeichert wurde.
==> positiver Wert
Bei Fehler : NULL
mode 3 : den Vektor an der Datensatz in der Datendatei
gespeichert wurde.
==> positiver Wert
Bei Fehler : NULL
Funktion : mode 1 : Speichert einen Datensatz in der Isamdatei.
Ist schon ein Datensatz mit dem in isamrec
angegebenen Key in der Isamdatei so wird
der negative Datendateivektor auf den Datensatz
in der Datendatei zurückgegeben.
Die Isamdatei bleibt unverändert.
mode 2 : Wird nach mode 1 ausgeführt wenn die Warnung
aus mode 1 ignoriert werden soll.
==> Rewrite
mode 3 : Speichert ein Datensatz in der Isamdatei.
Existiert schon ein Datensatz mit dem in isamrec
angegebenen Key so wird ein Rewirte durchgeführt.
Ist der Key noch nicht vorhanden, so wird
der Datensatz ganz normal neu angelegt.
Wichtig : Da isamwirte über den mode 1 und den mode 2 verfügt,
ist es nicht notwendig ein isamread() vor einem
isamwrite() auszuführen, um festzustellen ob schon
ein Datensatz mit dem aktuellen Key in der Datei
gespeichert ist.
Ist schon ein Datensatz mit dem Key, der in isamrec
angegeben ist, in der Isamdatei, so wird dies durch
Rückgabe des negativen Vektors auf den Datensatz in
der Datendatei angezeigt.
Dieser Vektor könnte z.B. für isamdatput() verwendet
werden, wie es auch in der Funktion isamwirte()
durchgeführt wird.
mode 3 ist kompatibel zu:
long isamwrite(void *isamhdl,void *isamrec)
von Version 1.00 und 1.01 (kein mode Parameter).
Isamseqread
-----------
Synatax : long isamseqread(void *isamhdl,void *isamrec, int mode)
Parameter: isamhdl: Isamdateihandle
isamrec: Pointer auf freien Speicherbereich
mode : bestimmt die Arbeitsweise der Funktion isamseqread
Rückgabe : mode 1 : NULL: - der Key, der sich an der Adresse
isamrec befindet, größer ist, als
der größte Key der Indexdatei.
- die Indexdatei leer ist.
Autor:
Lexolino



Kommentare
Kommentar veröffentlichen